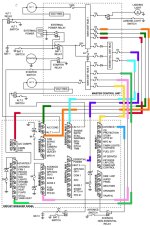
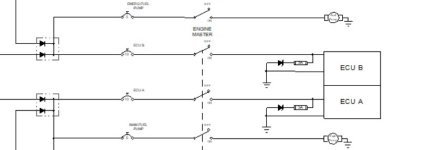
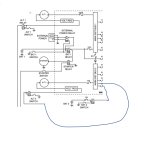
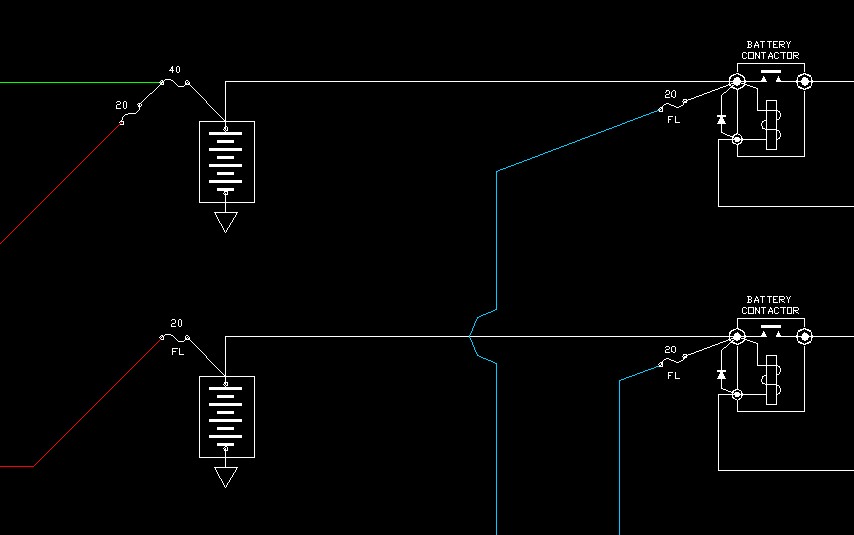
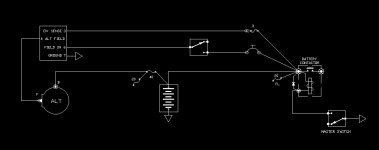
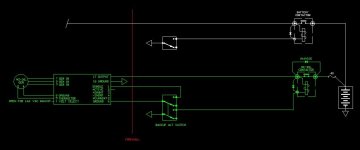
Not sure what you're talking about. Its a very simple concept. Put things on one bus, put things on another. If power supply goes offline from one, the busses get tied to keep everything powered.
Don’t disagree - it is a very simple concept. But what if the original failure could be put in the category of “malicious” - for example transient overvoltage from a generator or diode failure in an alternator rectifier circuit that puts AC on to the DC supply bus. Without adequate monitoring circuitry to automate the bus tie connect/disconnect or monitor crowbar circuitry to protect against particular failure modes connecting the two system strings together could result in complete loss of the system rather than partial loss of function. So we get to the concept of accepting an increase in overall system failure rate but gaining system availability by adding an automated busss tie with a high integrity monitor circuit. For vehicles and systems that require high levels of availability then system redundancy and complex high integrity monitoring may be the only answer.
For example Cat 3B autoland requires 3 autopilot channels all to be up and running before committing to land. The period of exposure is only 10 minutes but modern technology cannot make the availability or integrity number required with less than 3 independent very complex systems with redundant monitoring on each channel. The tentacles of complexity travel a long way into other systems for the auto-land case - I know its an extreme example but it makes the point about what it takes when the mission demands the capability. We dont have that demand (most of us) and are prepared to accept loss of function or degraded capability following a failure because without complex high integrity monitoring we could be making the situation much worse by tying the two strings together so goes the thinking. In the end analysis it depends on your level of scar tissue, experience and paranoia how you define your system architecture and develop your flight procedures following a failure. Balancing all of our systems design around the number one single point failure ( being single engine) and the associated failure rate which is likely some number in the 10-E4 range per hour puts us in the category of keeping it as simple as possible, living with either loss of function on a first failure or severely degraded capability following a first failure. Adding complex monitoring and system reconfiguration capability just gets us to a higher overall failure rate, more complexity in maintenance and troubleshooting without compensating benefits in availability.
Fly the first leg of a flight IFR with a full up system, fly the second leg of the flight or get back home in good VFR after the first failure could be one way to describe the philosophy.
Keith Turner
")





")